The monorepo architecture has certain advantages over polyrepo (or multi-repo) in some cases. However, implementing a successful monorepo is not easy, especially when it comes to automation, CI/CD, and build pipelines. For instance, there may be issues with long-running tests and releasing unchanged packages unnecessarily.
Based on my experiences, I will provide some solutions to improve automation.
Monorepo for Microservices
Obviously when we are talking about Monorepo architecture we are NOT talking about monolithic architecture.
Monorepo architecture vs Monolithic architecture
Monolithic architecture, also known as monolith, refers to a single solution that may consist of one or more projects. These projects are built as dependencies of a single project. When building the solution, the dependencies are built first and then used to build the main project. This type of architecture can be applied to various types of solutions, including full-stack projects such as MVC applications. However, in some cases, the monolithic architecture can become too large to manage from different perspectives.
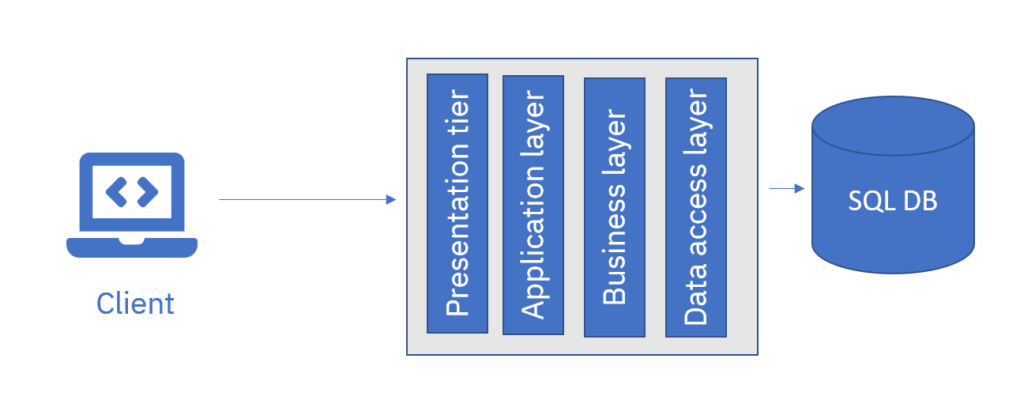
Monorepo architecture is the practice of storing multiple solutions within the same repository. These solutions can be thought of as small monoliths that work together to serve a common purpose. They can be services within a microservice architecture, or they may have some other relationship to each other, such as infrastructure as code and application.
Microservices architecture on a Monorepo
Although some people insist on separating repositories for different services and codes, there are cases where putting all or some of the services and codes in the same repository can be useful.
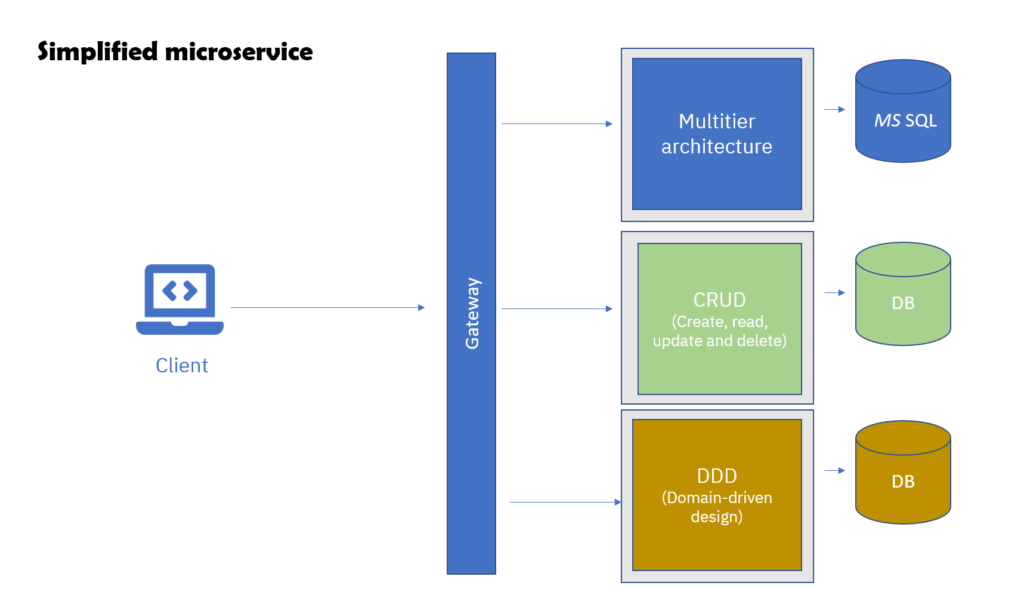
The “by the book” assumption of microservices architecture was that multiple teams, with different domain knowledge and technological expertise within a large organization, would work with different microservices. These people wouldn’t necessarily care about each other’s services, as long as they respected the agreed-upon contract (such as the API schema). However, this assumption is not always true in the real world. Teams are utilizing microservices for a variety of reasons, such as scaling, using serverless for some services, or even because they feel the monolith approach is considered outdated (that is a big mistake monolith is not outdated!).
When to use a monorepo
A monorepo is not necessarily a “no-no” as many teams choose this approach, such as GitHub’s private repo. It is particularly useful when a team works with multiple services, especially if those services have very similar code bases. Sometimes, there are shared in-house libraries, such as communication with a message queue, and creating a private package like NuGet or NPM Package would require extra steps. Additionally, some teams prefer to keep infrastructure as code (IAC) and/or database scripts near the code.
Moreover, using a monorepo allows for more structured and unified processes, such as the CI/CD process, package creation, and testing and releasing to the production server. Unified rules, such as formatting and code coverage, can be implemented as well.
Another advantage of a monorepo over a poly-repo is that it encourages teams to cooperate and engage in each other’s source code. This promotes innersourcing, from engaging in each other’s pull request review and feature requests to contributing code to each other’s codebase.
There is a case study at Google where you can read more about Advantages and Disadvantages of a Monolithic Repository
What to be careful about in a monorepo?
As previously mentioned, the first thing to consider is dependencies. Dependencies themselves are not inherently bad, but tight coupling is. Services should not depend on each other outside of the common area. If you make changes outside of the common area, it should not affect any other project. In other words, ensure that services are not dependent on each other.
Additionally, it is important to decide what happens when common libraries are updated. Who is responsible for updating dependent projects, and what is the process? Do all dependent reports get updated automatically? How do you handle it if some services want to stay in older versions of the library?
Security is also a crucial concern. The more people who have access to everything, the greater the potential for a hacker to make changes to sensitive information and deploy it. With everything automated these days, it is essential to be more cautious.
Speaking of security, it is important to ensure that no secrets are ever committed to the repository. This includes things like connection strings and API keys. Even if you delete them, hackers can still scan the git history and extract them from previous commits.
Long running tests can also be a problem. If every time you run a test you need to test all other solutions/services, as well as all integration tests, you may find yourself waiting longer and longer as the repository gets bigger. This should also be considered when setting up your monorepo.
Finally, repository issues can occur, such as when git status shows files as changed by mistake or when workflows do not function properly. This can interrupt all teams working with all projects and can be critical. It is essential to have a team responsible for fixing repository issues with very high priority.
CICD process in Monorepo architecture
If you decide to adopt a monorepo, optimizing your CI/CD process is essential. The goal is to run tests and build only the projects that have been changed, rather than everything that is in the repository.
Decide about structure
The first step is to have a well-structured folder system. You should decide in advance where things like IaC and documentation will be placed (either near their respective projects or in separate root folders) and come up with a pre-agreed upon structure. Here is an example:
-- Root
|--------- .github
|--------- tools
|--------- common
|--------- starter-templates
|--------- back-end
||------------------ dot-net
|||------------------------ project-abc
|||------------------------ project-xyz
||------------------ node-js
|||------------------------ ...
|--------- front-end
||------------------ node-js
|||------------------------ project-abc
|||------------------------ project-xyz
|--------- iac
|--------- docs Use Starter Templates
If you choose a monorepo, it makes a lot of sense to have all projects of the same type follow the same structure .For example, you can create a template for all DDD projects in .NET, another for CRUD projects in .NET, and so on. It is a simplifies the implementation of the Golden Paths repo templates.
Ensure that all the boilerplate building blocks (like logging, diagnostics, message queues, dependency injection, etc.) are similar (as much as it makes sense), even try the side car pattern if possible. This way, you get two benefits:
- When starting a new project, you can skip putting in many hours on boilerplate code.
- Programmers can jump to other projects and start contributing without the need to learn a new architecture and environment.
It is also much easier and safer to share CI/CD processes.
Trigger pipelines for what has changed
Although everything is in the same repo, most of the time you should consider each solution as a single entity. This means only running testing, building, versioning, and releasing for solutions that have changed.
To achieve this, you have two alternatives. The first is to add triggers manually to pipelines, and the second is to create some kind of automatic process to run pipelines based on chained folders.
Separate workflow for each path
In GitHub workflows, for example, there is an option called “path.” By using both the “branches” and “paths” filters, the workflow will only run when both filters are satisfied. This means that if a folder is changed, the workflow will start.
on:
pull_request:
branches:
- main
paths:
- 'dot-net/project-abc'Then you can make workflows specific to each folder project folder. This functionality though does not exist on azure devops but GitLab has rules:changes.
To make the path filtering more flexible, you can also use wildcards to apply the workflow to multiple projects. This is particularly useful when you have a well-defined folder structure. For example, using a path like ‘**/dot-net/**’ will trigger the workflow whenever a project written in dotnet is changed, regardless of its specific location within the repository.
Automatically detect changes in repo run cicd pipelines specific to what has changed
Another option is though to detect the changes and automatically run pipeline based on what has changed. To do that you can use git functionality. Though for shared CI/CD to work correctly you need to :
- have an strict folder structure (as mentioned before)
- projects are started from templates so they are to some degree similar to each other.
Test if the contents of a directory has changed
You can detect incoming changes at pull request time; the pull request ref points to state of merge of branch to target branch . Thus you can compare the current state of head to the head of branch that is being merged to using git diff command :
git diff --quiet HEAD^ HEAD -- "./a-folder-directory" || echo trueHEAD^ refers to the first parent, that always is the left hand side of the merge, so triggered by pull request, it means the branch that we are trying to merge to (ex. main). -- is just there to expect path after it. Thus, line above means we compare current head and first parent for the given directory. If the folder is changed we echo the word “true”.
Loop through the whole mono repo
When you do this type of automation, you want to get the folder paths , you should get a little bit creative; one way it to scan for files like *.sln , *.csproj, pom.xml, build.gradle, package.json, dockerfile ,and etc. Here is a loop looking for dotnet solution files :
find . -name "*.sln" -print0 | while IFS= read -r -d '' f; do \
DIR=$(dirname "${f}");
DIR_CHANGED=$(git diff --quiet HEAD^ HEAD -- "./$DIR" || echo true);
if [ "$DIR_CHANGED" != true ] ; then
continue;
fi
# Do your stuff here
done;
Lets us dissect the code above as it is relatively hard to understand bash script
find . -name "*.sln"This part is quite straightforward. It retrieves a list of all files with an .sln extension in the current directory (.) and all subdirectories.
The -print0 option separates the file names with a null character, which prepares them for the next step in the loop. The rest of line 1 creates a loop for each file name and puts each file name in the variable f.
Example file path: ./dot-net/project-abc/my-project.sln
Line 2: The dirname command extracts the path to the folder that contains the solution file, in this case ./dot-net/project-abc/.
Line 3: The if statement checks if anything in this folder has been changed. Note that echo true is how you assign “true” to the PATH variable. You cannot skip echo.
Lines 4, 5, and 6: If the folder has not changed, the loop moves on to the next iteration (note that you can also perform other actions between these lines).
Line 7: Now that you know that things inside the current path have changed ($PATH points to it), you can perform all of your CI/CD processes here (for example, test, build, publish, create a Docker image, etc.). Please feel free to use a shell function to keep your code clean and readable.
Note that in case of GitHub you need to make a deep checkout to fetch all history for all branches. (otherwise you get fatal: bad revision ‘HEAD^’ error) :
- uses: actions/checkout@v3
with:
fetch-depth: 0Release strategies
The challenge with a monorepo is that many people or teams may be working on the same repository simultaneously, and there may be a need for multiple releases per day. This issue needs to be addressed when dealing with a highly active repository. One solution is to use Trunk Based Development, where developers merge all code changes, including features and bug fixes, to a single branch, test it, and deploy it.
For example, Team1 creates a branch called “feature/abc-256/some-new-thing” and at release time, they merge it to the “trunk/date-time” branch, which contains other features and bug fixes from other teams, instead of merging it directly to the main branch. Then, the “trunk/date-time” branch is tested, and if everything is good, it is released and merged to the main branch.
However, you should not adopt this approach from day one. If you have a monorepo, but only one team makes changes occasionally, this approach may be more complex than necessary.
Leave a Reply