OpenAI’s text generator is a powerful tool for programmers and developers looking to enhance their applications with natural language processing capabilities. In this blog post, we will dive into the features and capabilities of OpenAI’s text generator, including its ability to maintain context like ChatGPT. Learn how OpenAI’s text generator can take your software to the next level, and discover the potential of natural language processing for your business.
ChatGPT, which is a part of OpenAI’s text generator, has gained a lot of attention in recent months, particularly from influencers who have touted its potential for generating high revenue. However, many of these claims have been found to be scams. While it is true that ChatGPT has a wide range of potential applications, it is important to approach these claims with a critical eye. The reality is that for programmers and developers, ChatGPT is a valuable tool that can help to enhance their applications with natural language processing capabilities. It’s important to understand the real potential of ChatGPT and not to get caught in false promises of easy money. If you are a programmer, it’s worth exploring the possibilities of how you can use this technology to improve your software and take it to the next level.
The Impact of OpenAI’s Text Generator on Programmers: Separating Fact from Fiction
As with any new technology, there is always the concern that it might replace jobs. Some programmers may worry that OpenAI’s text generator, and specifically GitHub Copilot that is based on same technology as chatGPT, will take their jobs. However, it is important to understand that while this technology may change the way that programmers work, it is unlikely to replace them entirely. Similar to how voice recognition technology has not replaced the keyboard, OpenAI’s text generator will not replace the need for programmers.
In fact, this technology should be seen as an opportunity for programmers to enhance their skills and improve their work. The text generator’s ability to maintain context and support multiple languages can and will replace some details of the job, such as ‘searching and stackoverflowing’, allowing programmers to focus on more complex and creative work. Additionally, this technology can also open up new possibilities for software development and bring new opportunities for businesses. Overall, OpenAI’s text generator and ChatGPT should be seen as an opportunity for programmers to evolve and improve their skills, rather than a threat to their jobs.
OpenAI’s text generator and its capabilities
OpenAI’s text generator is a state-of-the-art machine learning model that is capable of generating human-like text. It is built on the transformer architecture and pre-trained on a massive amount of data, allowing it to generate text that is coherent and contextually appropriate. One of its key features is ChatGPT, is that it can maintain a stateful conversation and switch between multiple languages. This makes it a powerful tool for various use cases such as customer service chatbots, language translation, and more.
Explanation of ChatGPT and its Role in the Text Generator: ChatGPT, which stands for “Conditional Generative Pre-training Transformer,” is a component of OpenAI’s text generator. It is a machine learning model that is pre-trained on a large dataset of text, allowing it to generate human-like text. ChatGPT is specifically designed to handle conversational language, making it a powerful tool for applications such as customer service chatbots and language translation.
OpenAI models
The OpenAI API is a set of machine learning models that can understand and generate natural language, code and can detect whether text is sensitive or unsafe. The API is powered by different models with different capabilities and price points. The main models are GPT-3 which can understand and generate natural language, Codex( limited beta) which can understand and generate code, including translating natural language to code, and Content filter which is a fine-tuned model that can detect whether text may be sensitive or unsafe. The GPT-3 models include Davinci which is the most capable, Curie which is very capable and faster, Babbage which is capable of straightforward tasks, and Ada which is capable of very simple tasks. Each model is suitable for different tasks, and OpenAI plans to continuously improve their models over time. They may use data provided by users to improve the accuracy, capabilities, and safety of the models. You can read in details in
Playground
OpenAI Playground is an online platform that allows users to interact with the OpenAI API and its models in a user-friendly interface. It provides a way for users to experiment with the models and understand their capabilities without needing to write any code. One of the models available on OpenAI Playground is text-davinci-003.
Text-davinci-003 is the most capable model in the GPT-3 series, capable of performing any task that the other models can do, often with higher quality, longer output, and better instruction-following. It also supports inserting completions within text. This model is suitable for applications that require a lot of understanding of the content, like summarization for a specific audience and creative content generation. It’s trained on a large dataset of text up to Jun 2021.
OpenAI Playground provides an easy way for users to test text-davinci-003 capabilities and fine-tune it for specific tasks. The playground allows users to input a prompt and see how the model responds, giving them a better understanding of the model’s capabilities and how to use it for their specific use case. It’s a great way for developers and researchers to test the model’s capabilities and fine-tune it for their specific needs, without the need to write any code.
As shown in the image below, the OpenAI API gives the impression of maintaining a stateful conversation.
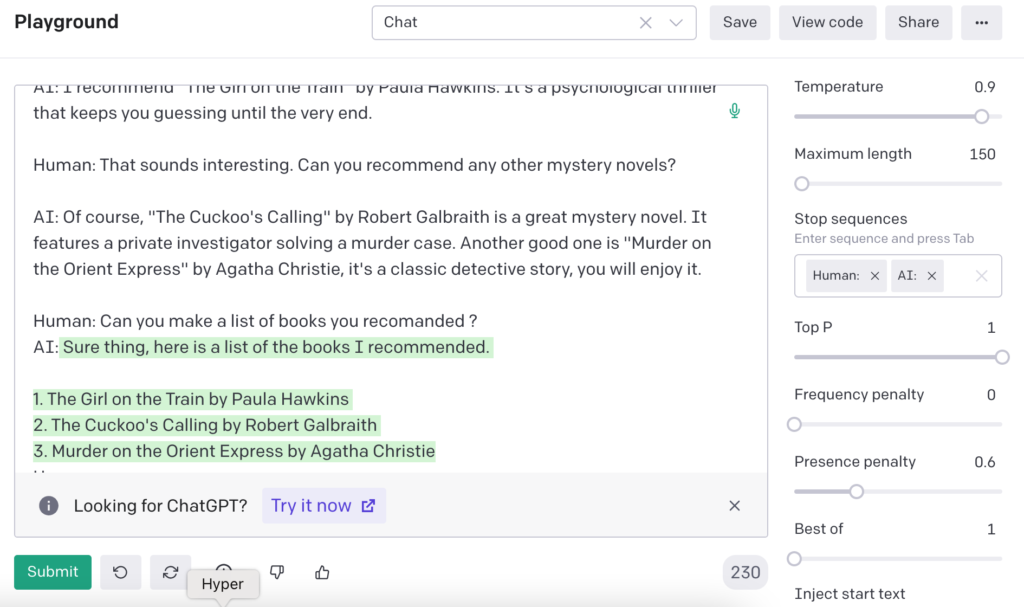
Code the Stateful bot
The OpenAI API is a set of machine learning models that can be used to perform a wide range of natural language processing tasks, such as text generation, language translation, and sentiment analysis. The API is designed to be easy to use and accessible to developers of all skill levels, providing a simple, RESTful interface for interacting with the models.
The API also supports multiple languages, making it a versatile tool for global applications. Additionally, it offers different models with different capabilities and pricing points, allowing users to choose the model that best suits their needs and budget.
Users can also customize the base models for their specific use case with fine-tuning on the OpenAI Playground, an online platform that allows users to interact with the OpenAI API and its models in a user-friendly interface.
If you look at the API call it looks like this :
curl https://api.openai.com/v1/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "text-davinci-003",
"prompt": "Your Question here ",
"temperature": 0.9,
"max_tokens": 150,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0.6,
"stop": [" Human:", " AI:"]
}'But it I does not have any session or context to keep track of a conversation, so from the perspective of the API each call is new conversation, how does the Chat GPT keeps track of context of previous dialogs.
One of the advanced features of the OpenAI API is the ability to send the previous conversation in the prompt when interacting with a stateful model such as ChatGPT. This allows the model to maintain a context and continue the conversation based on previous interactions.
When interacting with the API, users can pass in a prompt that includes the previous conversation. The model will then use the context from the previous conversation to generate a response that is coherent and contextually appropriate. This can be especially useful for creating more natural and human-like interactions, such as in a customer service chatbot or virtual assistant.
In order to use this feature, the previous conversation needs to be passed in the prompt in the form of a string, with a specific separator, such as “\n” between the previous conversation and the new prompt, this will allow the model to understand where the previous conversation ends and the new prompt starts.
The previous conversation can be stored in the application’s state, database or any other storage system, and passed to the API with each new user input.
Here is how our prompt looks like, note how smart is the davinci-3 being able to understand the conversation from before and gets the answer with regard to that :
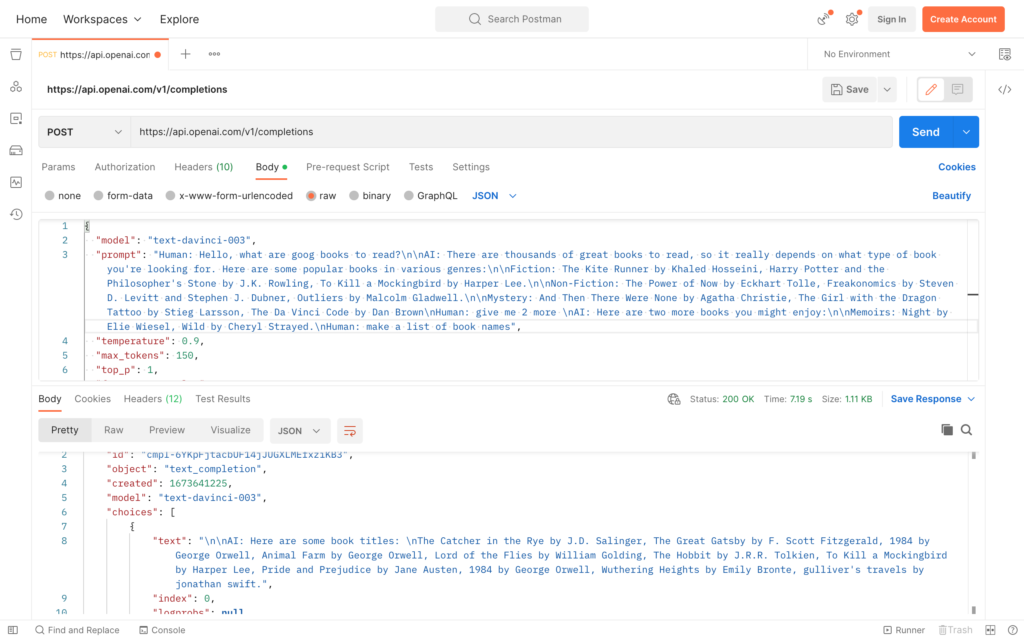
Limitation and optimization
The OpenAI API uses a token-based system to limit the amount of text that can be generated in a single request, and the cost of an API request depends on the number of tokens generated and the specific model being used. For example, text-davinci-3 has a maximum request of 4,000 tokens, this includes both prompt and the generated response.
Each token represents a word or a piece of punctuation in the generated text. You can think of tokens as pieces of words, where 1,000 tokens is about 750 words. The more tokens that are generated, the more complex and detailed the text will be. However, it’s worth noting that generating more tokens also increases the cost of the API request. Requests are billed based on the number of tokens in the inputs you provide and the answer that the model generates. If you make an application for use users and it each call of your app costs you about 4000 tokens, you are going to have rather high costs.
To ensure optimal performance and lower the token usage, an idea is to keep a few of the latest statements in the conversation while summarizing the rest of the conversation time to time. This can be achieved by implementing a buffer mechanism that stores the recent statements and discards the older ones. By doing this, you need a smaller set of tokens to represent the current context of the conversation, resulting meeting the limit as well as containing as much as context as possible. Your backen can ask the Openai API to summarize; it can be as simple as adding “\n\n Summarize conversation” to your current state.
Fine-tuning your model for your application
Fine-tuning is a process that allows you to customize a pre-trained model for your specific application. The benefit of fine-tuning is that it can provide higher quality results than prompt design, the ability to train on more examples than can fit in a prompt, token savings due to shorter prompts, and lower latency requests. It works by training a model on many more examples than can fit in the prompt, allowing it to achieve better results on a wide number of tasks.
To fine-tune a model, you must first prepare and upload your training data in the form of a JSONL document. Each line should consist of a prompt-completion pair, which corresponds to a training example. The OpenAI command-line interface (CLI) provides a tool to easily convert your data into this format. Additionally, the CLI allows you to create a fine-tuned model using the openai api fine_tunes.create command. This command uploads the file, creates a fine-tune job, and streams events until the job is complete. The fine-tuned model can then be used for your specific application, with the added benefit of lower costs and lower latency requests. Read more about fine-tuning
Use cases for Stateful Text Generator
An stateful AI powered conversation backend has a wide range of potential use cases in various industries. One of the most popular use cases for stateful GPT-3 based system is in customer service chatbots. These chatbots can use GPT-3’s natural language processing capabilities to understand and respond to customer inquiries, providing efficient and accurate assistance. Additionally, Stateful Text Generator can also be used to power language translation applications, allowing for seamless communication between people speaking different languages.
Other use cases for Stateful Text Generator based on openai include:
- Content creation: can be used to generate high-quality text, including articles, blog posts, and even books.
- Social media: can be used to generate captions, hashtags and even comments to social media posts.
- E-commerce: can be used to power conversational interfaces such as chatbots on e-commerce websites, helping customers to find products and complete purchases.
- Healthcare: can be used to generate medical reports, summaries of patient history and even to assist in the diagnosis process.
These are just a few examples of the many potential use cases for stateful AI powered system. With its natural language processing capabilities, GPT-3 based system can be used to enhance and improve many different types of applications, making it a valuable tool for businesses and developers alike.
Leave a Reply